Data Readiness Evaluation
Assess the freshness, quality, lineage completeness, and reproducibility of existing data pipelines.
AI systems fail when the data feeding them becomes inconsistent or difficult to reproduce over time. Tabsdata provides a real-time, reproducible data foundation that lets teams deploy AI with confidence and explain results long after models are in production.
By shifting dataflows into a declarative, table-centric model, Tabsdata removes pipeline fragility and delivers the governance, transparency, and operational stability required for enterprise AI adoption.



AI initiatives often struggle not because of model quality, but because the underlying data is difficult to keep fresh, consistent, and traceable.
For AI engineers, data scientists, and ML platform teams, the foundation that matters most is the data feeding the model.
Tabsdata acts as a real-time data backbone for AI by ensuring:
Metadata, semantics, and governance built directly into the architecture.
With Tabsdata, teams can depend on every feature, transformation, and dataset powering their models to behave correctly, consistently, and compliantly. There is no need for manual pipeline maintenance.

Tabsdata provides a structured, enterprise-grade framework to evaluate whether your data, pipelines, and governance foundations are ready to support AI at scale.
This assessment helps teams identify gaps in freshness, lineage, reproducibility, and operational stability before models reach production. It follows a structured, repeatable framework and serves as a clear on-ramp to production deployments.
Assess the freshness, quality, lineage completeness, and reproducibility of existing data pipelines.
Evaluate how batch, micro-batch, and real-time pipelines support both training and inference, and where latency or inconsistency may impact accuracy.
Review traceability, drift detection, auditability, and compliance alignment.
Analyze readiness for real-time scoring, high-volume feature updates, and large-scale AI deployments.
Validate controls for safe AI operation, including monitoring, access governance, and responsible AI thresholds.
AI initiatives often stall because the data foundations are not ready for production scale.
Delayed or batch-updated features directly reduce model accuracy and decision quality.
Missing lineage slows debugging and increases compliance risk.
Inconsistent inputs make validation unreliable.
Operational overhead slows ML delivery and innovation.
Legacy ETL/ELT systems were not built for real-time feature delivery.
When data is untraceable or inconsistent, adoption drops.
Companies trust Tabsdata because it reduces uncertainty across the full lifecycle of AI systems, from experimentation to long-running production models.
Tabsdata replaces fragile pipelines with a declarative dataflow model where freshness, reproducibility, and traceability are guaranteed by design.
The same inputs always produce the same outputs. Declarative propagation removes hidden execution paths and reduces failure modes common in ETL and streaming pipelines.
Features update as source data changes, while immutable versions and time travel allow experiments, training runs, and decisions to be reproduced later.
Every transformation, dependency, and dataset version is tracked automatically. Lineage is native, not reconstructed, enabling reliable audits, faster debugging, and confident impact analysis.
Fewer moving parts mean fewer failures. When issues occur, deterministic behavior and full lineage make root cause analysis faster and more reliable.
Tabsdata supports continuously operating models such as fraud detection and personalization, where fresh features, strict consistency, and post-incident explainability are non-negotiable.

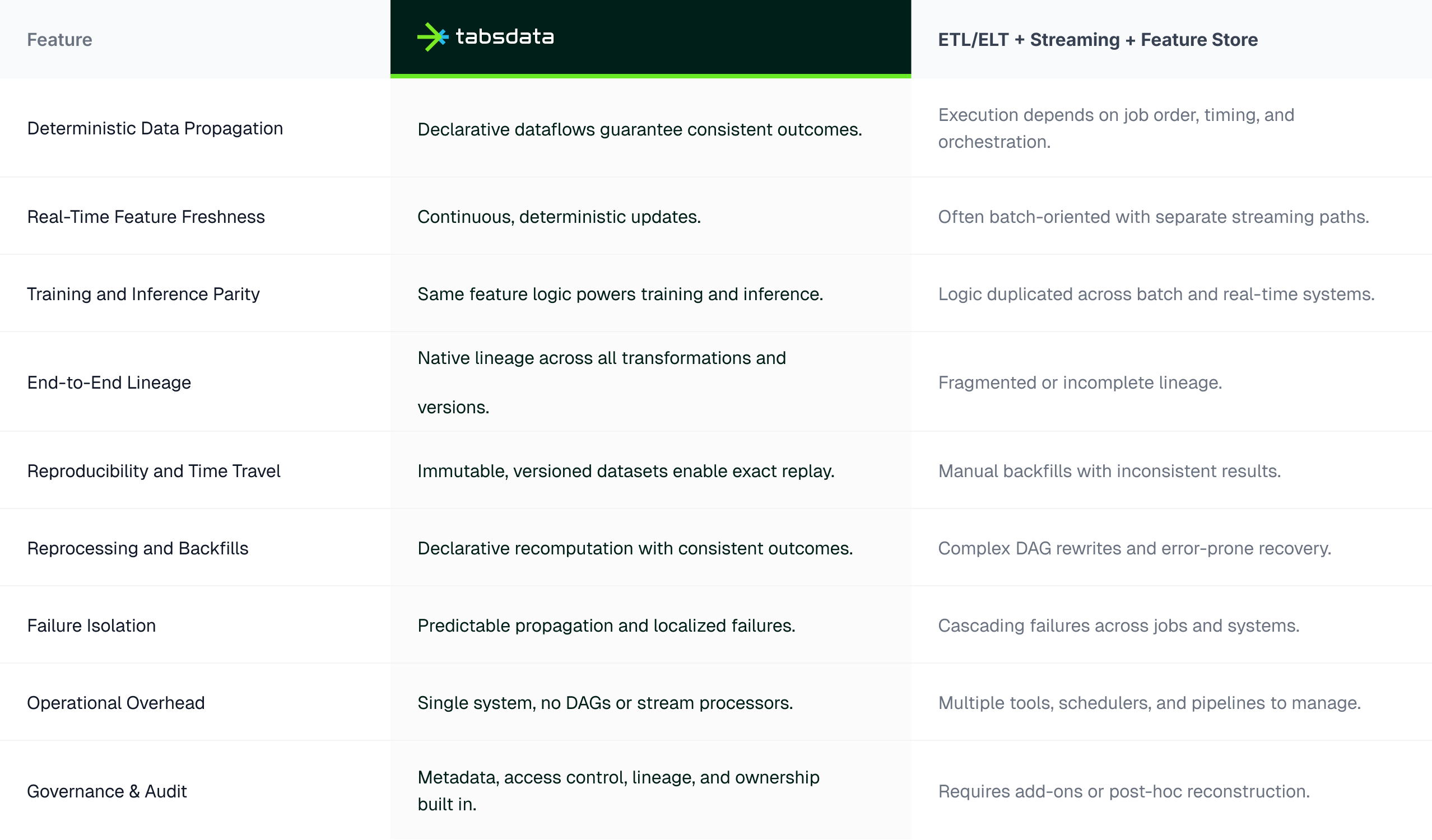

This foundation allows teams to evaluate AI and ML use cases in production-like conditions, using real data, real workloads, and real governance constraints
Tabsdata gives AI and ML teams real-time, reproducible data foundations required to scale models confidently into production. By eliminating fragile pipelines and delivering continuously up-to-date, fully traceable features, Tabsdata removes the operational barriers that slow AI adoption..
Can’t find the answer you’re looking for? Please chat to our friendly team.