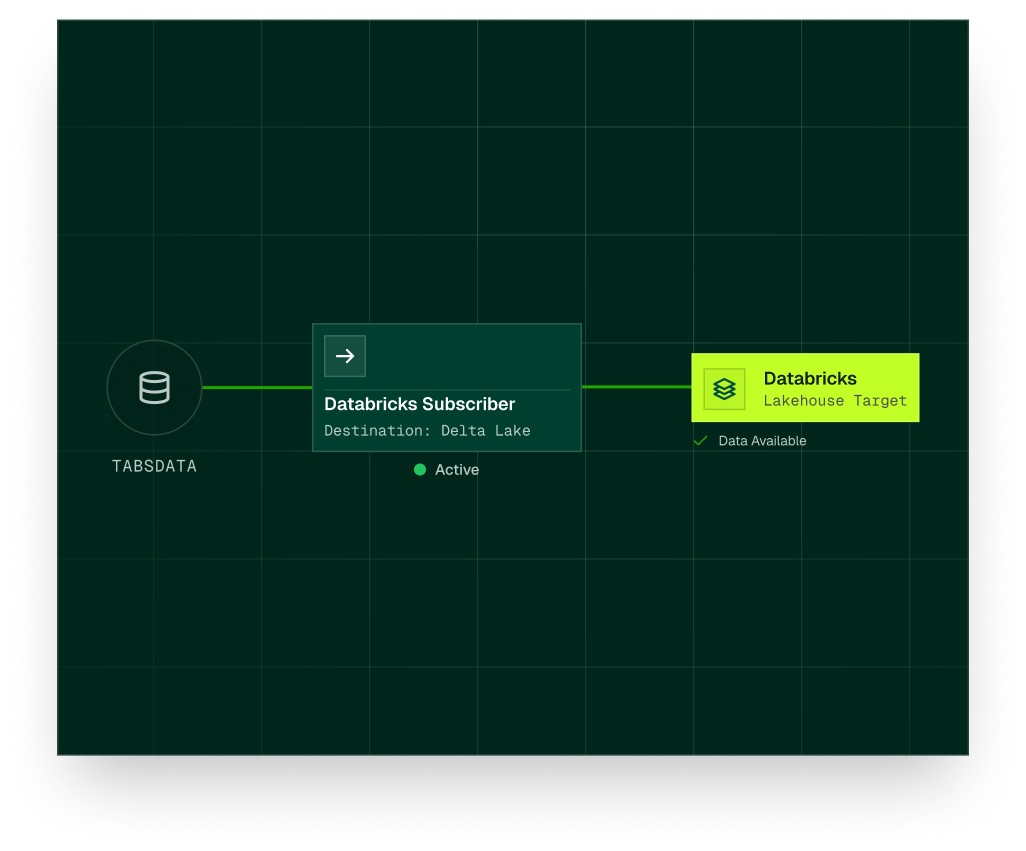
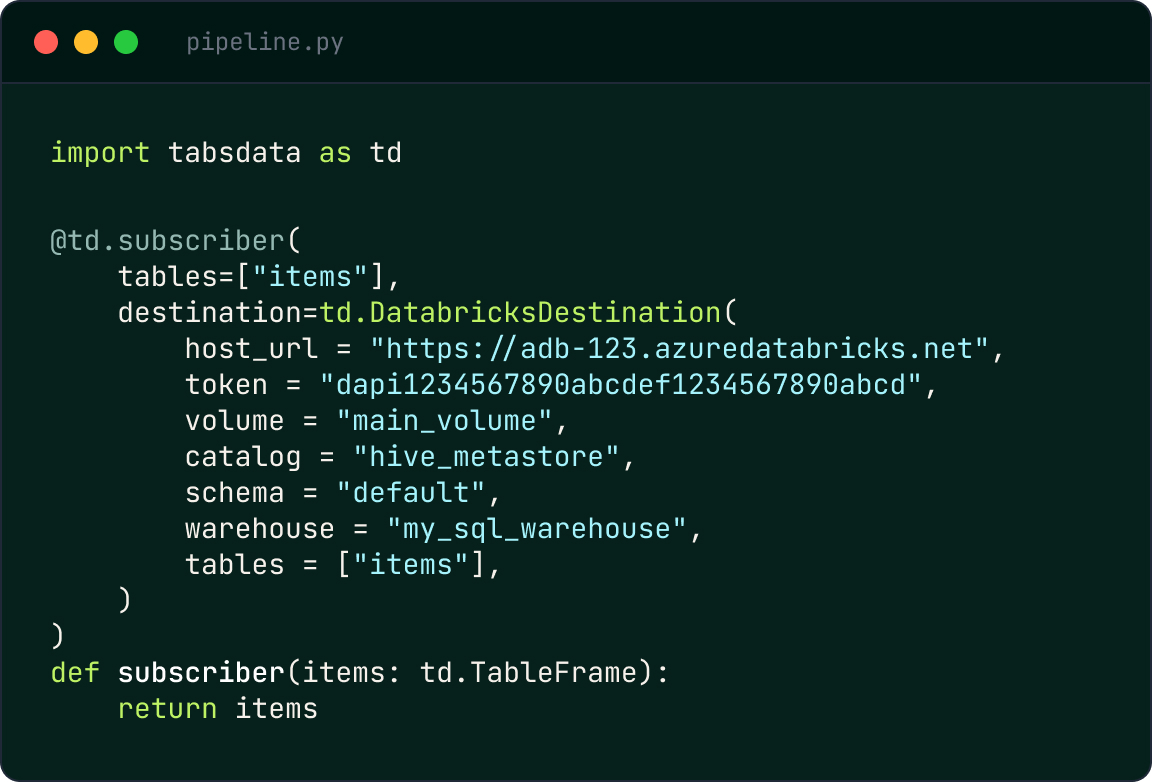
The Tabsdata + Databricks integration connects Tabsdata’s declarative dataflow engine with the Databricks Lakehouse Platform. Delta tables act as downstream subscribers within the Pub/Sub for Tables execution model, receiving new immutable table versions automatically as soon as they are published.
Rather than relying on scheduled ETL jobs or long-running streaming pipelines, table versions are automatically propagated based on declared dependencies. This ensures that data written into Databricks remains consistent, auditable, and aligned with upstream business logic, without partial refreshes or table state skew.