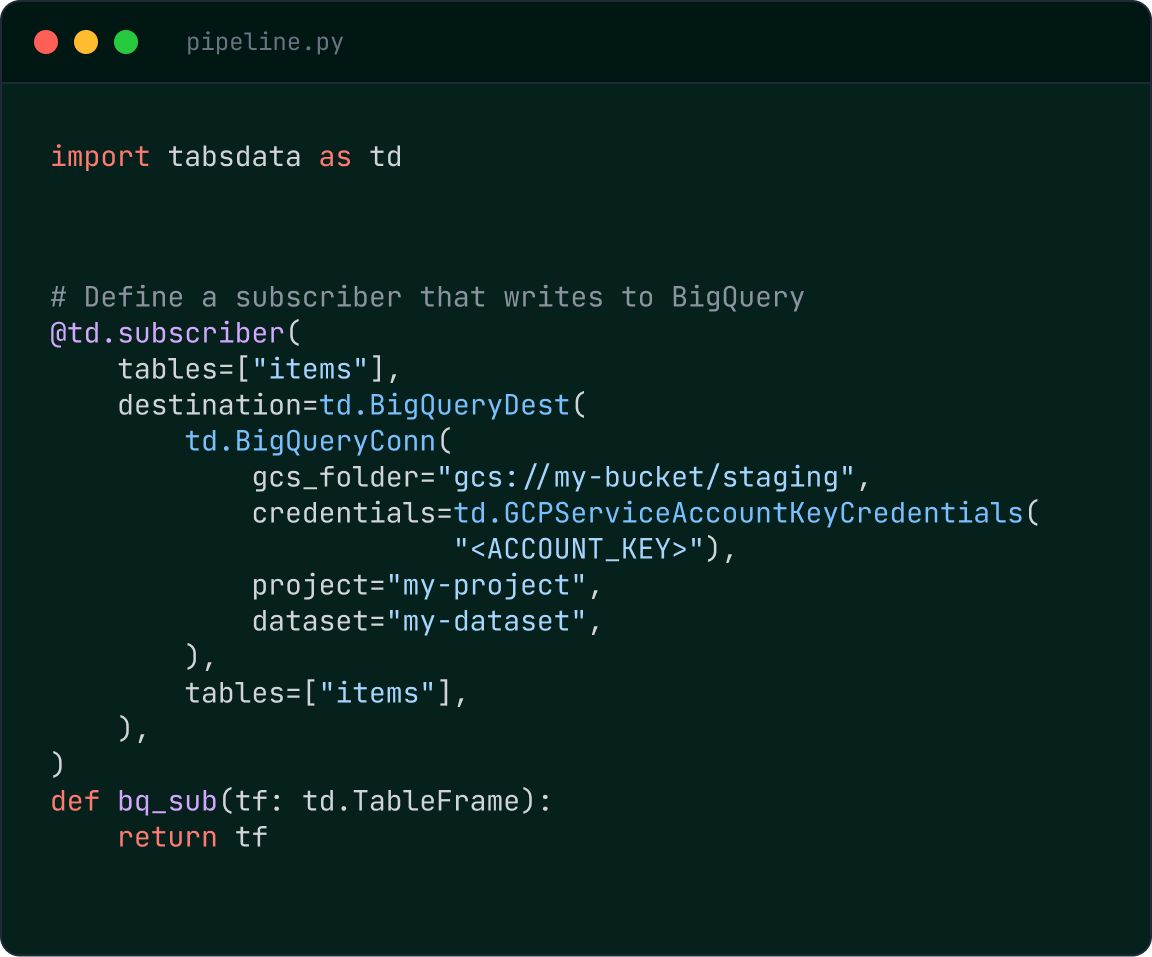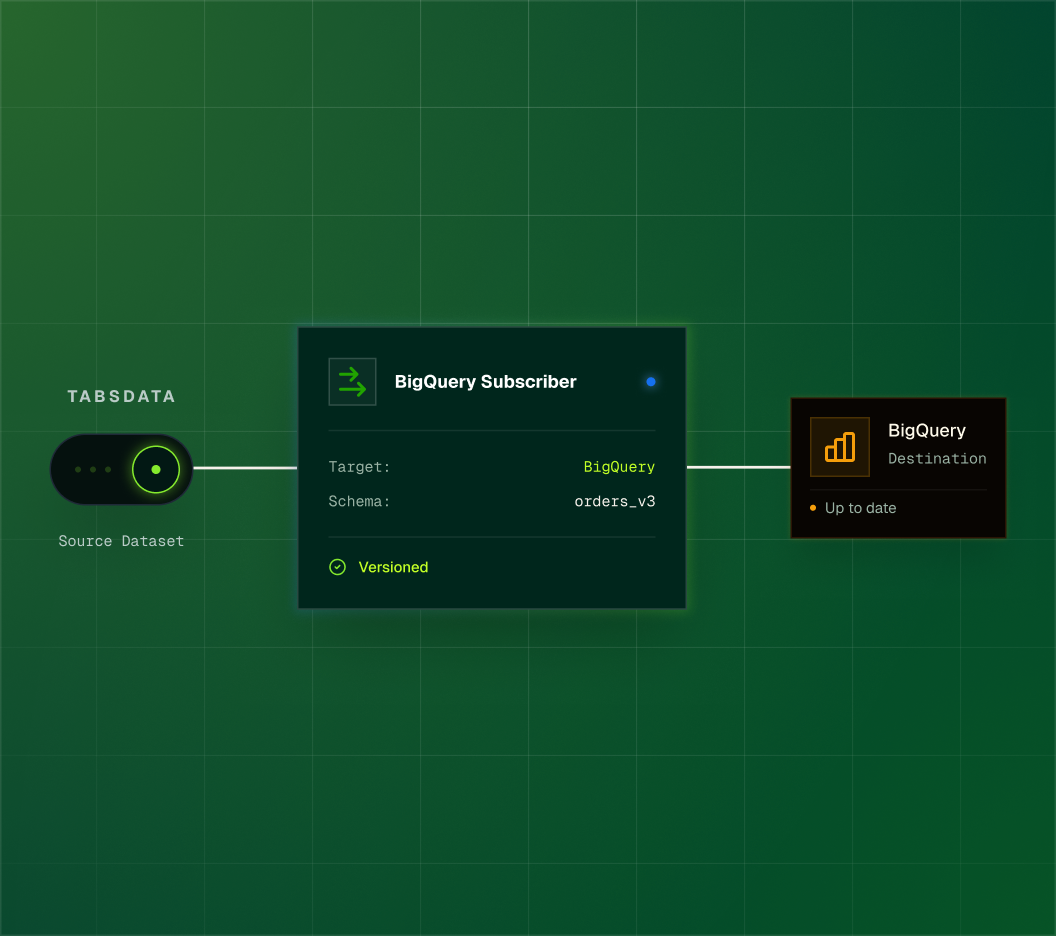


Real-Time Deterministic BigQuery Table Updates
Tabsdata publishes changes as new immutable table versions and propagates them directly into BigQuery tables. Each publication produces a complete table version that is applied deterministically, ensuring analytics and downstream consumers operate on a consistent data state.