The Architecture Behind Tabsdata’s Declarative Dataflow Engine
Tabsdata is a deterministic real-time ETL system designed to ensure consistent data across analytics and AI. It replaces manual pipelines and fragmented orchestration with a deterministic publish/subscribe (pub/sub) execution model for tables. The system autonomously computes execution order based on declared table dependencies, eliminating the need for manual workflow wiring.
Deterministic execution ensures that the same published data always produces the same downstream table versions across all consumers. Data only moves between verified states to maintain business logic integrity and prevent downstream systems from observing partial or inconsistent results.
To provide full auditability, the system tracks the lifecycle of every table version from origin to consumption.
Functional Entities
Tables are the fundamental, versioned units of data. Functions act as publishers, transformers, or subscribers operating on tables. Collections define logical boundaries for sets of tables and functions aligned to business domains.

Programming Model
Developers interact with Tabsdata through a declarative Python API. Transformations are performed using a Tableframe API similar to Pandas or Polars. This programming model allows transformation logic for analytics and AI to run on the same deterministic data path while Tabsdata manages execution complexity.

Product Architecture
Tabsdata manages real-time data flow while maintaining strict, deterministic consistency. The system uses a reactive pub/sub execution model where publishing a table automatically triggers execution of all dependent tables and subscribers. The engine analyzes table relationships as a directed acyclic graph derived from declared dependencies. It supports self-dependencies where a function reads prior versions of the same table it writes to.
Pristine State ensures that downstream systems always consume consistent, version-aligned data across multiple business domains. Functions produce new table versions atomically, in their entirety or not at all. If a transaction fails, all generated table versions within that transaction are discarded. Pristine State extends beyond individual transactions by ensuring data consumed across business domains remains consistent.

Versioning and Time Travel
Table versions are immutable. Every new version becomes an available snapshot that enables exact time travel for analytics and AI workloads. This provides built-in support for slowly changing dimensions and full reproducibility of historical data states.

Data Quality
Tabsdata incorporates data quality as a core component of the execution model rather than an external layer. Declarative validation rules are defined alongside transformation logic and evaluated as part of the same transactional boundary. If a data quality check fails, the collection does not transition to a new Pristine State.

Governance
Governance is an automatic outcome of the data flow. Lineage tracks high-level movement among tables, while provenance provides record-level tracking. Lineage and provenance are preserved. Furthermore, because previous table versions are immutable and their execution metadata is retained, you can observe these relationships exactly as they existed at any point in time, deterministically.


System Architecture
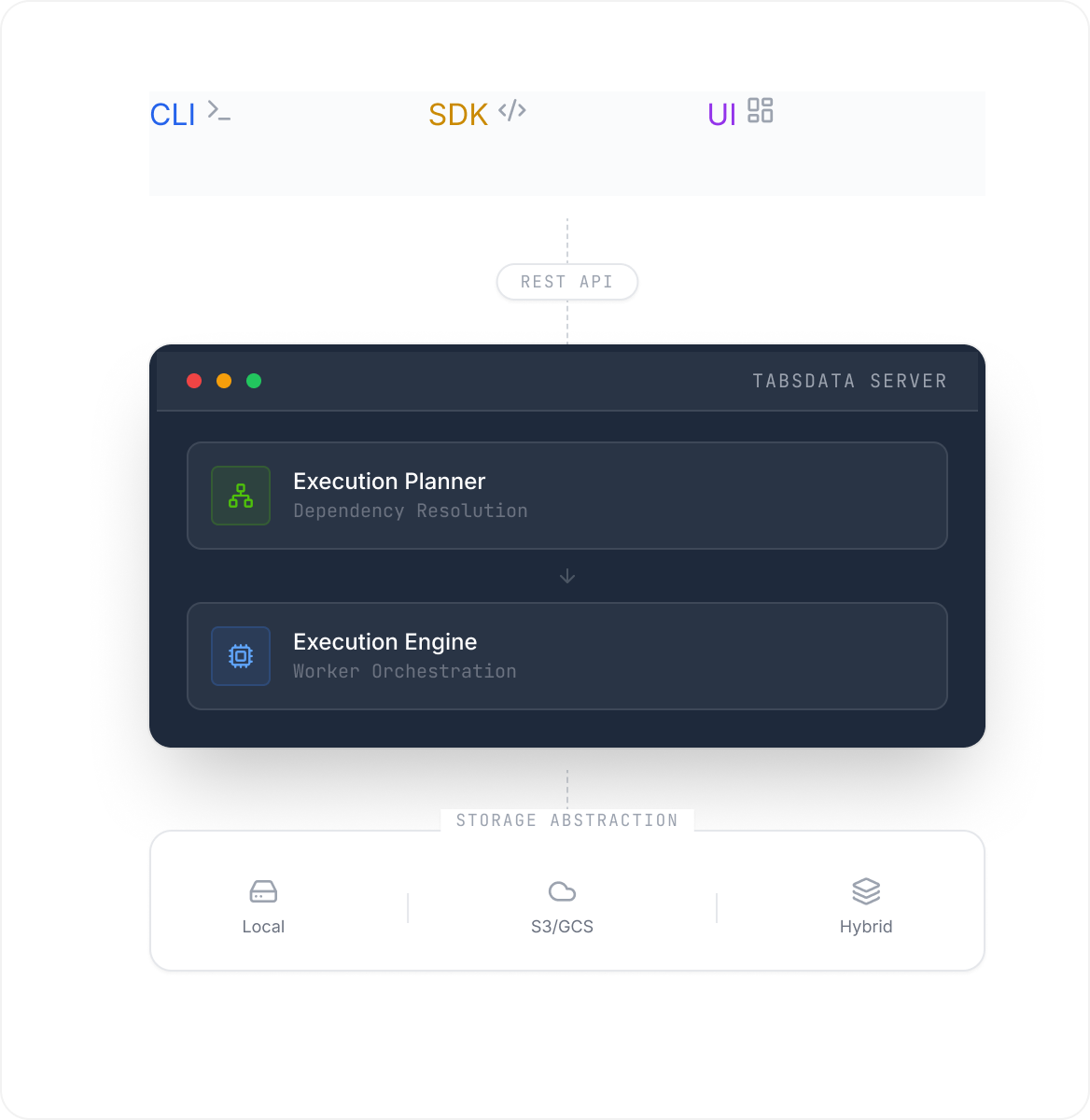
The Tabsdata server is implemented in Rust and Python and communicates with CLI, SDK, and UI clients through a REST API. The server core consists of specialized management modules for identity and access control, object lifecycle management, connection metadata, integrity management, execution planning, and storage management.
Execution planning is separated from execution. The Execution Planner derives deterministic execution plans based on declared table dependencies, while the Execution Engine deploys these plans across isolated workers. This separation ensures deterministic and consistent planning even as execution scales from across standalone to Kubernetes-based deployments.
Each function runs in its own isolated environment to prevent dependency conflicts. Storage management abstracts over local disk, cloud object storage, and hybrid configurations, enabling scalable and high-throughput data access.
Architecture FAQs
Still have questions?
Can’t find the answer you’re looking for? Please chat to our friendly team.