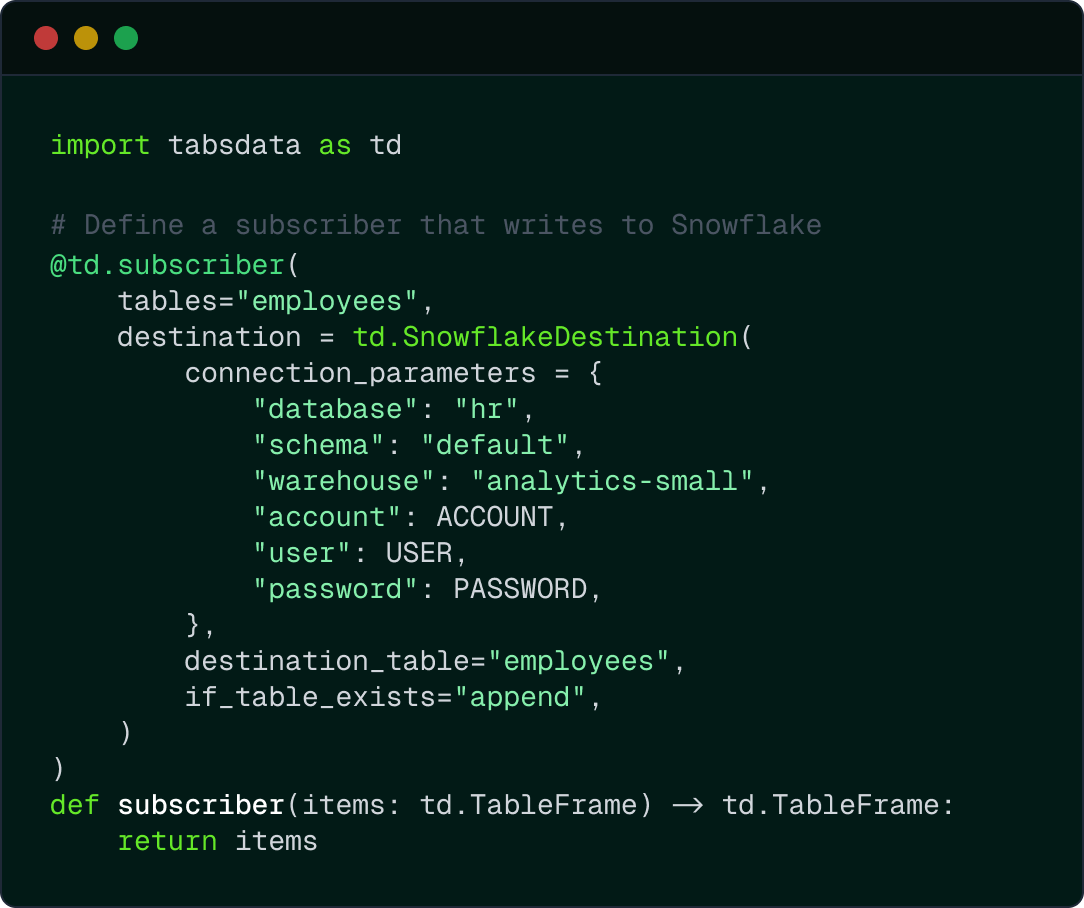
Real-Time Data Propagation into Snowflake
When new data is published, a fresh immutable table version is created and automatically propagated to Snowflake through declared dependency relationships. Updates propagate in deterministic order, allowing Snowflake to reflect a consistent data state across related tables without manual coordination.
This avoids scenarios where dashboards, reports, or downstream consumers observe mismatched table states due to asynchronous refresh behavior.