
Recently, I ran a series of benchmarks comparing the open source offerings for Tabsdata and Airbyte across several common data integration workflows. Both tools operate in the data integration space, but they have very different scopes and architectural approaches.
Airbyte is strictly a point-to-point data mover, designed to move data from A to B. Although it provides some minimal row-level transformational capability and a dbt integration, both of these options are only available in their paid offering.
Tabsdata, on the other hand, is a complete data platform. It handles point-to-point movement just like Airbyte, but extends far beyond that to manage complex multi-step orchestration and heavy-duty transformations like joins, aggregations, and UDFs. It also provides built-in automatic data versioning, lineage, and observability.
Although extract and load is only a small subset of what is possible with Tabsdata, I wanted to see how Tabsdata performs when restricted entirely to Airbyte’s home turf of simple point-to-point data movement workflows.
To test this, I read data from S3 and Postgres sources and wrote it to Postgres, Snowflake, and AWS Glue Iceberg destinations. I chose these systems to represent the variety of systems used by Data Engineers in our current landscape (Relational Databases, Data Warehouses, Data Catalogs, Object Storage)
As the benchmarks show, even when restricting Tabsdata to this narrow use case, it operates faster and more efficiently in most scenarios.
TL;DR
Across the tested workflows, each system showed strengths depending on the type of infrastructure being used.
- Postgres → Postgres: Airbyte was 1.8× faster
- S3 → Postgres: Tabsdata was 2.5× faster
- Postgres → Snowflake: Tabsdata was 3.2× faster
- Postgres → AWS Glue Iceberg: Tabsdata was 6.1× faster
- S3 → Snowflake: Tabsdata was 22.5× faster
- S3 → AWS Glue Iceberg: Tabsdata was 86.2× faster
In general:
- Airbyte performed best when moving data between traditional relational databases
- Tabsdata performed best when moving data between data catalogs, data warehouses, and object storage
Environment, Architecture, and Dataset Specs
All benchmark infrastructure was deployed in AWS. The source data layer consisted of an AWS RDS PostgreSQL instance (db.r7g.large) provisioned with 2 vCPUs, 16 GB of RAM, and 200 GiB of gp3 storage with 3,000 provisioned IOPS, alongside AWS S3 for object storage. The compute layer was run on an AWS EC2 m7i.4xlarge instance with 16 vCPUs and 64 GB of memory, running RHEL 10.1. For destination infrastructure, data was written to multiple systems, including the same AWS RDS PostgreSQL instance that was used for the source, AWS Glue (Data Catalog), and Snowflake using an X-Small warehouse.
The NYC Taxi and Limousine Commission (TLC) publishes its taxi data publicly, and I collected taxi data spanning June 2023 through November 2025 to build a 107 million row dataset, alongside 1 million and 10 million row derivatives. I then loaded all three datasets into my source systems with the following specifications:

I designed six workflows by combining each source system (S3 and Postgres) with each destination system (AWS Glue, Snowflake, and Postgres). Each workflow was run against all three dataset sizes (1 million, 10 million, and 107 million rows). Every workflow and dataset combination was executed five times, and the results were averaged across runs.
All three datasets were used to evaluate how each tool performs across different data sizes, while all reported metrics, including IOPS, throughput, and total processing time, were calculated using the largest dataset available during testing (107 million rows).
Benchmark Numbers
Raw benchmark numbers from our tests can be found: here
Interactive versions of the various graphs in the post can be found here
Writing from Object Storage

For tests using S3 Object Storage as a source, Tabsdata was anywhere from 2.5x to 86.2x faster than Airbyte when processing the same dataset.
Airbyte’s performance was consistent regardless of the destination system. When reading from S3, it performed at a throughput of about 0.1 MB/s and an IOPS of 5,500 rows/second, taking about 5.5 hours to process the 107 million row dataset in every test.

Tabsdata was faster than Airbyte across all three tests, and had varying performance depending on the destination system. When writing from S3 → AWS Glue, Tabsdata performed the strongest at 8.9 MB/s and 479,000 rows/second. Writing to Snowflake, Tabsdata performed at 2.28 MB/s and 122,000 rows/second. Writing to Postgres showed the weakest performance of 0.26 MB/s and 13,000 rows/second

Writing from Relational Databases

For tests using a Postgres database as a source, the performance gap between Tabsdata and Airbyte was narrower. Tabsdata was up to 6x faster in some cases, while Airbyte was up to 2x faster in others.
Airbyte’s performance again remained largely unaffected by the destination system. However, it was significantly faster when using Postgres as a source compared to S3. Across all three tests, Airbyte maintained a throughput of around 4 MB/s and an IOPS of 22,000 rows/second, completing the 107 million row dataset in slightly under 1.5 hours per test.
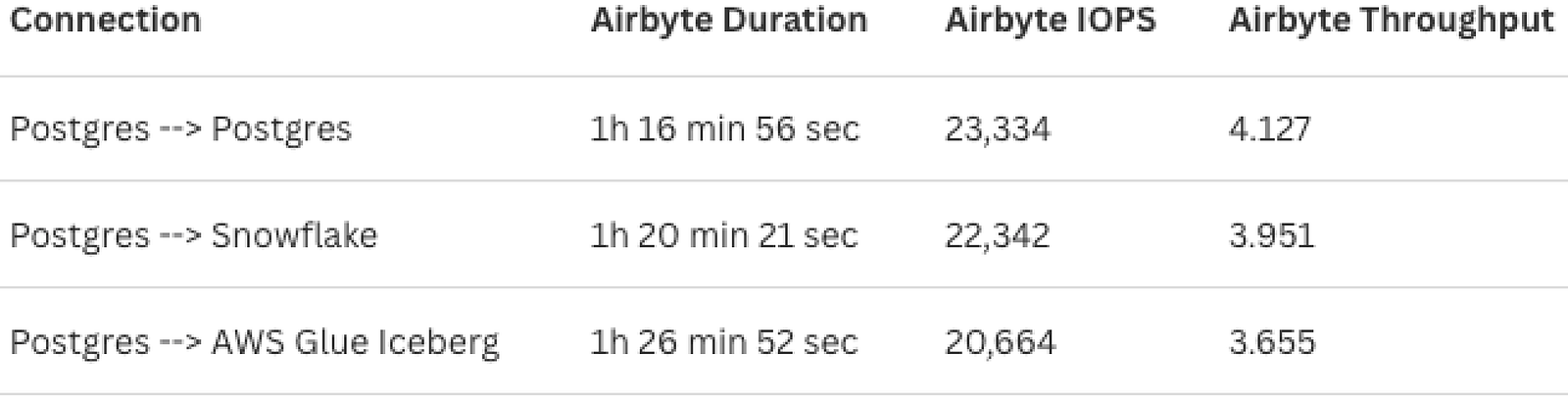
Tabsdata’s performance, by contrast, varied depending on the destination. It outperformed Airbyte when writing from Postgres to AWS Glue and Postgres to Snowflake, achieving throughputs of around 22 MB/s and 12 MB/s, with corresponding IOPS of 126,000 rows/second and 71,000 rows/second. However, when writing from Postgres to Postgres, Tabsdata performed at 2.27 MB/s and 12,800 rows/second, which was around half the speed of Airbyte for the same workflow.

Observations
Airbyte performs strongest with traditional databases
Airbyte showed its strongest performance when moving data between row-oriented databases. Airbyte’s Postgres-to-Postgres workflow processed about 23k rows/sec, making it 2× faster than Tabsdata for the same workflow.
Airbyte’s streaming model works well here because it reads chunks of rows from the source and immediately streams them to two parallel workers, each with an independent connection to the Postgres destination. It’s kind of like two cashiers at a supermarket. A second cashier doesn’t make each transaction faster, but the line moves twice as fast. Tabsdata writes at the same speed per connection but runs a single worker instead of two, so it processes half as many rows at a time.
The other factor is sequencing. Tabsdata’s publisher has to fully finish before the subscriber starts. This is by design, since operations like joins and aggregations require the full dataset to be materialized first. Airbyte has no transformation layer, so it starts writing to the destination the moment the first record leaves the source. For a straight Postgres-to-Postgres workflow with no transformations, that’s a meaningful head start.
Tabsdata performs strongest with modern analytical data platforms
Tabsdata showed its strongest performance when moving data between data warehouses, data lakes, and object storage. Tabsdata’s S3-to-AWS Glue workflow processed 478k rows/sec, making it 86× faster than Airbyte for the same workflow, completing in 3 minutes and 45 seconds what took Airbyte 5.5 hours.
The core difference is that Parquet file upload and SQL row insertion are not the same operation. A single Parquet file with 1 million rows lands in S3 in one bulk transfer, with none of the single-connection write saturation that slows down SQL insertion into databases like Postgres. Airbyte’s streaming model, even with concurrent workers, writes data in small chunks as it arrives from the source, which produces hundreds of small files in S3 that Glue has to scan one by one, hurting both write and query performance.
Tabsdata materializes the full dataset into large Parquet files before the subscriber runs, which is exactly what tools like Snowflake, S3, and Glue are built to work with.
Tabsdata’s Parquet-native architecture, which requires full dataset materialization before writing, becomes a structural advantage for communicating with modern data platforms that speak parquet natively.
Processing Time

Throughput (MBs Processed per Second)

IOPS (Rows Processed per Second)

The results show a clear difference between the two tools depending on the type of system the data is moving between.
Airbyte outperformed Tabsdata in workflows like Postgres → Postgres
Tabsdata, on the other hand, outperformed Airbyte in every other workflow, with performance gains ranging from 2x — 86x faster for identical workflows.
Next Steps
These benchmarks only cover a small subset of possible workloads. Future tests will explore:
- Larger datasets
- Additional data integration tools
- Different source and destination systems
- Incremental Syncs with Postgres CDC and WAL
- Workflows that include transformation steps
I will also be releasing Terraform scripts that allow anyone to replicate these benchmarks and run the tests themselves.