One of the core features of Tabsdata is the control and granularity it gives you to adapt your Tabsdata instance to your data stack. You get an array of out of the box connectors that make it easy to connect to services like AWS, Postgres, MySQL, and many more.
But, how does Tabsdata integrate so smoothly with so many different data systems and platforms? And what happens if you need to connect to an external system that is not covered by the standard connectors?
In this article in our Tabsdata Deep Dive Series, we will look at the piece of Tabsdata that makes connecting to external systems a breeze: the Plugin.
Quick refresher on Tabsdata architecture
In a Tabsdata Server, you have Tables and Functions. Tables act as persistent storage for your data and Functions interface with Tables to either read or write data into them. Together, Tables and Functions work together to Publish, Transform, and Subscribe your data between a various array of data systems and platforms.
A Tabsdata function is comprised of two parts that work together to propagate your data:
- The Function decorator
- Defines the inputs your function body will receive
- Defines where the data returned by the function body will go
- The Function body
- Takes the inputs provided by the decorator as arguments
- Does work on provided arguments
- Whatever the function body returns is loaded into the destination defined in the decorator
Publisher Anatomy

Since Publisher functions write data from external systems into Tabsdata Tables, the source parameter defines the input for the function body and the tables parameter defines where data returned by the function body will go.
Transformer Anatomy

Since transformers read from Tabsdata Tables and write into new Tabsdata Tables, the input_tables parameter defines the input for the function body and the output_tables parameter defines where data returned by the function body will go.
Subscriber Anatomy

Since Subscriber functions write data from Tabsdata Tables out into external systems, the tables parameter defines the input for the function body and the destination parameter defines where data returned by the function body will go.
What are Plugins:
A Plugin is what a Tabsdata Function uses to interface with external systems.
Consider the Publisher Function above that uses the Out-of-the-Box Local File System connector to publish data from a file called employees.csv into a Tabsdata Table called employees.
How does Tabsdata know what to do with the file path we provide? There are several steps in reading data from that path correctly and we need to ensure Tabsdata can execute those steps properly. This is why the file path is passed as an argument inside a something called td.LocalFileSource.
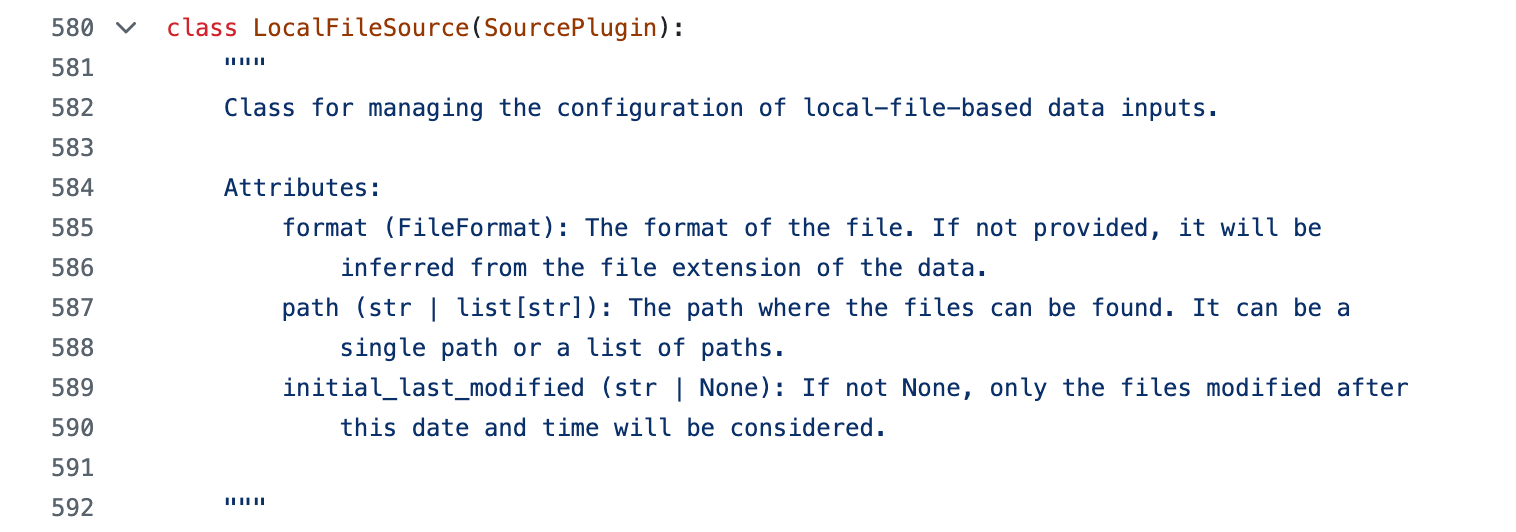
td.LocalFileSource is a Plugin, or a class that contains all the instructions for taking the provided file path and fetching the correct data from your local file system. This way, we only need to provide the file path within the function and Tabsdata handles everything else under the hood.
While the code for reading a file path into Tabsdata might not look very complicated, things change quickly once you move beyond local files. Tabsdata ships with connectors for services like Postgres, MySQL, Amazon S3, Oracle, Salesforce, and many more. Each of these systems has its own protocol, authentication method, and required inputs. Rather than forcing you to write boilerplate logic in every function to handle these differences, Plugins abstract that complexity away. You just call the appropriate Plugin, provide the necessary parameters, and you're good to go!
Anatomy of a Plugin

Under the hood, these classes do quite a lot, but for the purposes of this blog, three class methods are very important to cover.
_run()
Private method that is executed and runs all downstream methods. You will never overwrite this method directly, however it is especially important for destination plugins as it is responsible for removing internal metadata fields from your Tabsdata Table data and passing the cleaned data into your downstream methods.
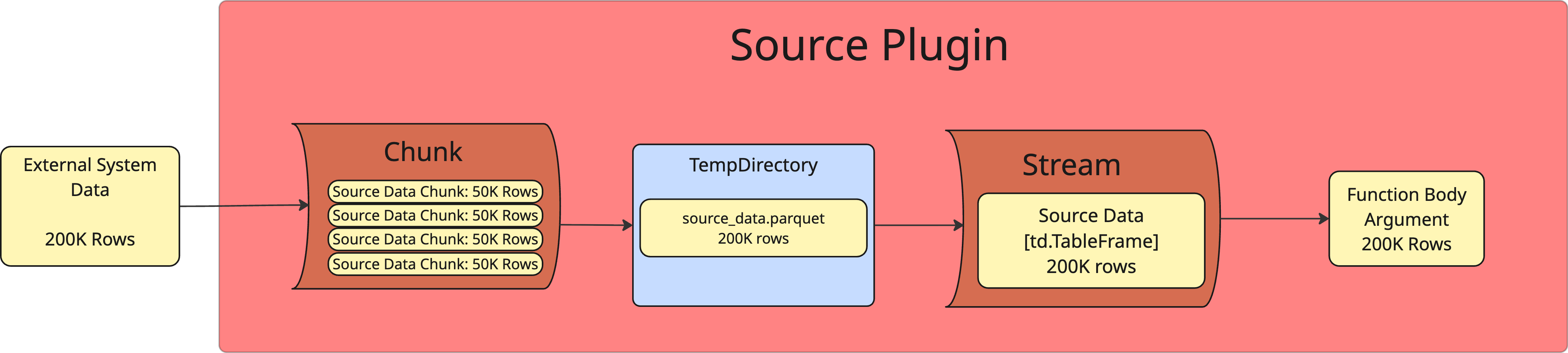
chunk()
To avoid throttling memory in scenarios where the data size of source data is very large, the chunk method allows you to introduce logic for breaking the raw data into smaller chunks prior to passing it downstream.
The chunk method must:
- Store your data as one or more parquet files in a working directory dynamically defined by the plugin class.
- Return a list of filenames stored in the working directory. For source plugins, the filenames returned become positionally mapped to the arguments passed into the function body.
stream()
Reads parquet data staged by chunk() and hands it off to the next step of the workflow.
- For Source Plugins used by Publisher Functions, stream pushes data from the working directory to the function body
- For Destination Plugins used by Subscriber Functions, stream pushes data from the working directory to an external system
write() [For DestinationPlugins]
Decouples reading parquet data from working directory and loading the data into an external system. For destination plugins, stream only passes the file paths returned by the chunk method() to the write() method. The write() method then reads the parquet data from the file path, converts it into the appropriate file type, and loads it into the destination system
From a technical standpoint, the plugin class calls the _run() method, which calls the stream() method. The stream() method then calls the chunk() method, which writes the raw data into parquet files in Tabsdata's working directory and passes the file paths for the parquet files downstream. However, for the simplicity of understanding the purpose of each class method, we can use the visual above to understand the steps from the perspective of the data flow from source → destination
Standard Plugins vs Custom Plugins
Even with Tabsdata's wide set of standard connectors, you may want to publish from or subscribe to a service that does not yet have a standard Tabsdata connector.
This is where Custom Plugins come in. Tabsdata Connectors have an architecture that grants you full freedom to create your own custom connectors from scratch.
This is possible because all Tabsdata connectors, custom or standard, live in a shared inheritance hierarchy and are subclasses of one of two base classes, SourcePlugin and DestinationPlugin. Think of these two classes as templates for a connector that act as blank canvases for you to fill in with the logic that makes your connector do certain tasks.
To help drive the point home, here is the class definition for the LocalFileSource connector that reads local system data into Tabsdata Tables
And the class definition for the LocalFileDestination connector which writes Tabsdata Table data into the local file system

Notice that both connectors inherit the SourcePlugin class and DestinationPlugin class respectively.
Connectors diverge from these base classes by overriding and adding methods that allow Tabsdata to accomplish specific tasks. Overriding methods such as chunk() and stream() is also the foundation for building your own custom plugins from scratch.
How to Make your own Source Plugin
Source Plugin Structure
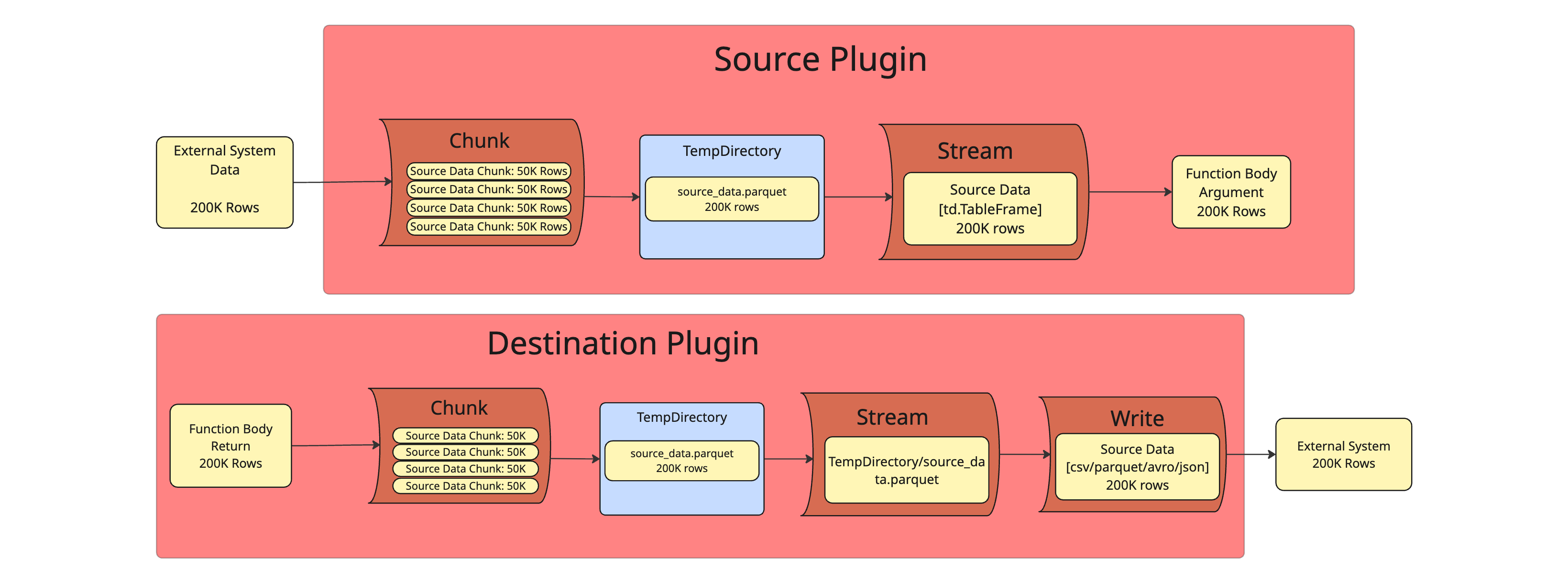
Source Plugins are used by Publisher Functions and passes data from an External System to the Function Body as an argument (or set of arguments)
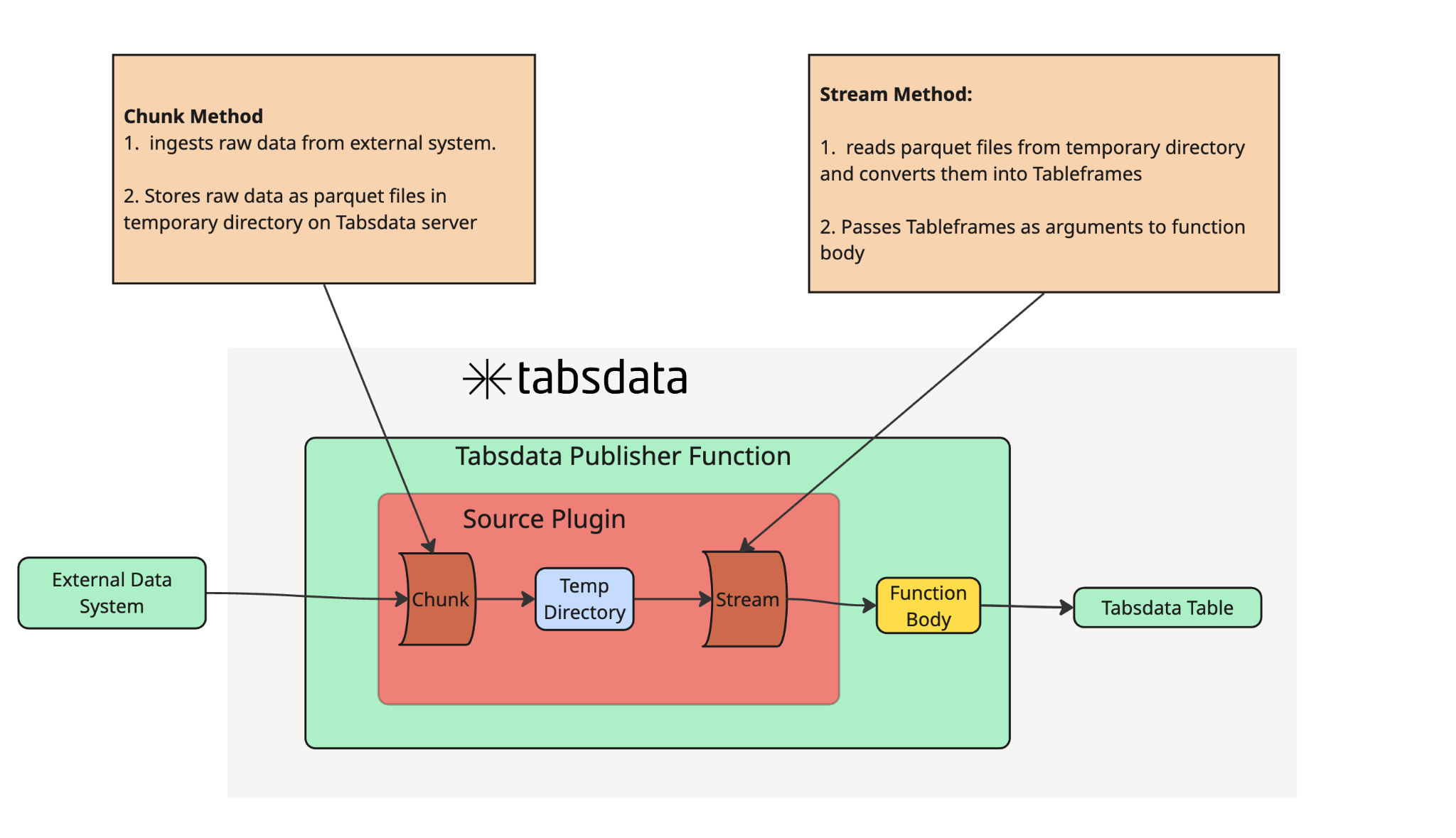
For Source Plugins, the chunk() method fetches external data, in chunks if necessary, and writes the dataset into a temporary working directory on the Tabsdata server in parquet format. The stream method reads the parquet data from the working directory and converts the data into a Tableframe, which is analogous to a polars lazyframe, and passes the Tableframe as an argument to the function body.
Source Plugin Instructions
In order to create your own Source Plugin, you will need to create a new class that inherits the SourcePlugin class and then overwrite the class's chunk method. In the overwritten chunk method, you must do the following steps
- Acquire the data you would like to pass into your function body
- Write that data as a parquet file into the working directory. Tabsdata defines this directory within the class constructor at runtime, so you don't have to worry about creating it yourself. Your chunk method simply accepts a
working_dirargument containing the directory path and uses it when saving files. - Pass the filenames of your parquet files into the return statement
Attached below is a sample Tabsdata Publisher that uses a Custom Source Plugin below. In this function, we ingest weather data from a free weather api called Open-Meteo into Tabsdata

When the function runs, Tabsdata constructs your Plugin and calls chunk(). chunk() pulls the data from Open Meteo, writes it as a parquet file into the working directory, and returns the file names of the parquet files. Tabsdata then reads those files, catalogs and validates them, and passes the resulting TableFrames to your function body.
How to Make your own Destination Plugin
Destination Plugin Structure
Destination Plugins are used by Subscriber Functions and bring data returned by the Function Body to your External System
For Destination Plugins, Tableframe data returned by your function body is cleaned, chunked if necessary, and written as parquet data into the working directory by the chunk() method. The write() method then reads the parquet data from the working directory, converts it into the proper file type, and loads it into the external data system.
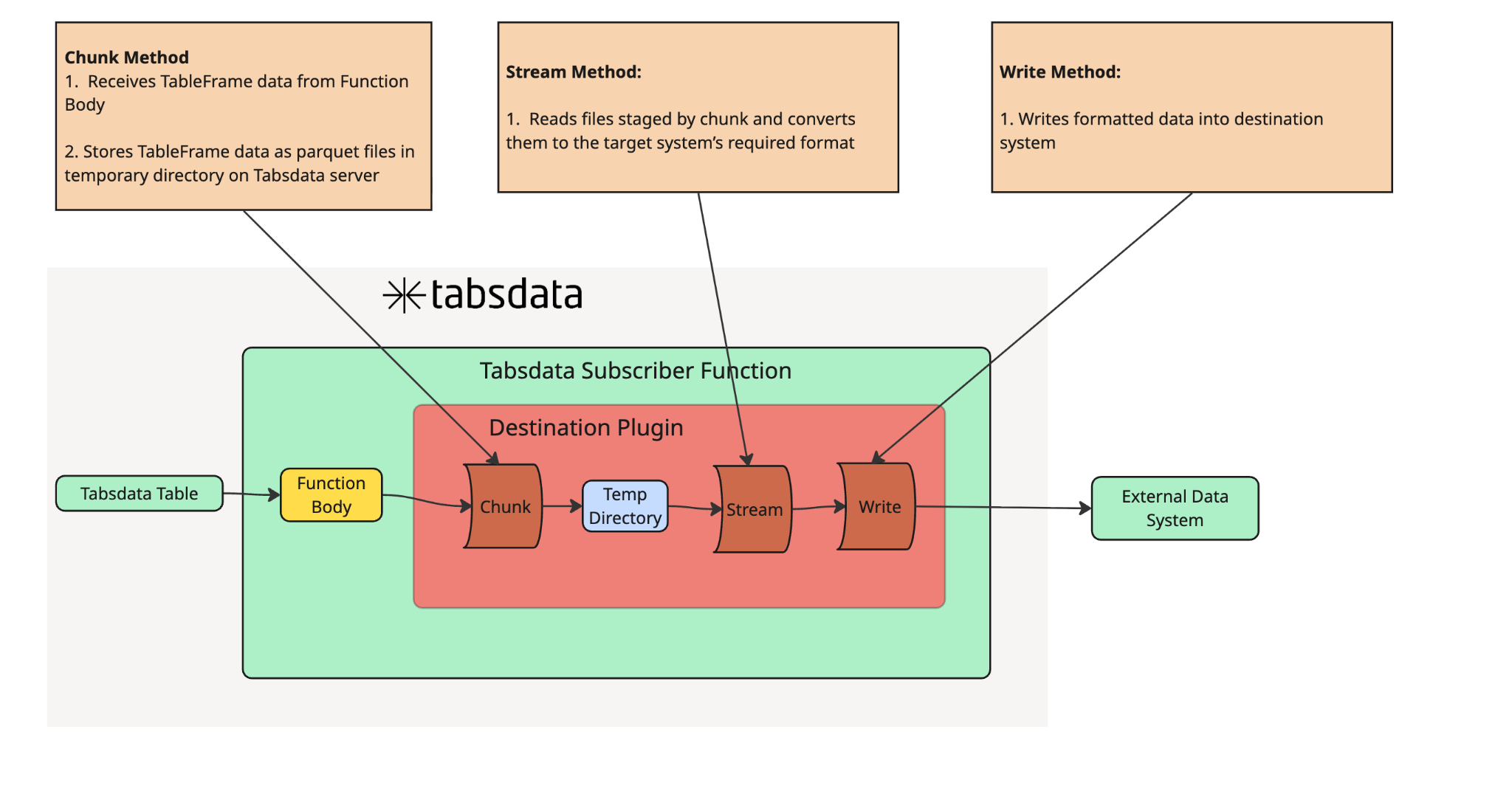
Destination Plugin Instructions
In order to create your own Destination Connector, you will need to create a new class that inherits the DestinationPlugin class and then overwrite the stream method with your custom logic.
In the overwritten stream method, you write the logic to upload your Subscriber’s data into your destination system.
Attached below is a sample Tabsdata Subscriber Function that uses a custom Destination Plugin. In this function, we send data from a Tabsdata Table into GCP as a CSV file.
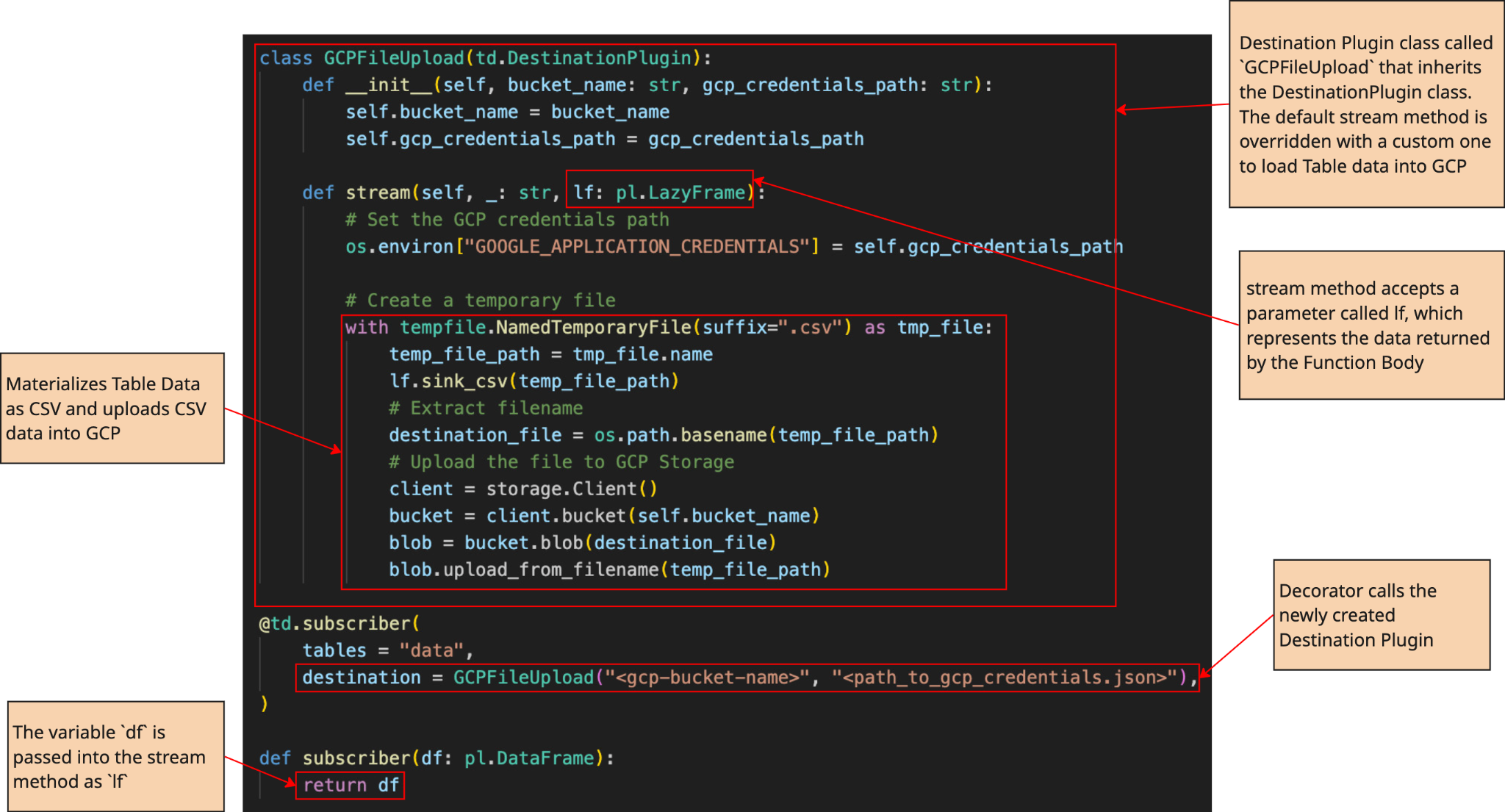
When the subscriber runs, Tabsdata constructs your plugin, GCPFileUpload, and calls stream. Stream receives the Tabsdata Table’s data as a parameter called lf, writes it to a temporary CSV file, and uploads that file to your Google Cloud Storage bucket using the service account credentials you provide.
*NOTE: If chunking of your data is required, this can be accomplished by leaving the stream() method as is and overwriting the chunk() and write() methods. In the scenario, chunk() will break your Tabsdata Table data into multiple parquet files and store them in a working directory. Your write() method will receive a list of filepaths for these parquet files, convert them into the appropriate file type, and load the data chunks into your destination system.
Conclusion
Plugins make Tabsdata flexible, extensible, and able to integrate with virtually any data system. Out-of-the-box connectors let you get up and running quickly, but the real power comes from the ability to build your own. By inheriting from SourcePlugin or DestinationPlugin and overriding the chunk or stream methods, you can design a connector tailored to your exact needs.
This architecture ensures that no matter what tools your data stack depends on, Tabsdata can be configured to easily work with them.